
Wie funktioniert das Internet-Protokoll HTTP?
Ganz einfach: der Client (Webbrowser) sendet eine Anfrage (GET), das Protokoll über das angefragt wird und zwei leerzeilen. Anschließend bekommt der Browser vom Server die Seite ausgeliefert:
als Browser
Auf der Linux-Shell kann eine solche Abfrage mittels Netcat (nc) und echo nachgebildet werden:
echo -e "GET / HTTP/1.1\r\nHost: www.heise.de\r\n\r\n" | nc www.heise.de 80
Die Anfrage „GET / HTTP/1.1“, die Mitteilung zu welcher Domain die Anfrage gehört (host:) und zwei Zeilenumbrüche (\r\n) werden mittels Netcat an Port 80 des Servers www.heise.de gesandt.
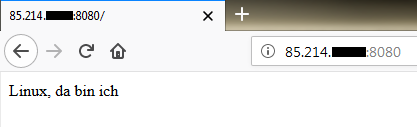
als Server
Auch ein HTTP-Server lässt sich auf der Linux Schell auf die gleiche weise „simulieren“:
echo -e "HTTP/1.1 200 OK\r\nContent-Type: text/html\r\n\r\nLinux, da bin ich"|nc -l 8080
Beim Aufruf der Seite in einem Browser erscheint der Text „Linux, da bin ich“ und auf der Shell erfolgt die Ausgabe des Anfrage Headers.
GET / HTTP/1.1
Host: 85.214.55.47:8080
User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:58.0) Gecko/20100101 Firefox/58.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: de,en-US;q=0.7,en;q=0.3
Accept-Encoding: gzip, deflate
Connection: keep-alive
Upgrade-Insecure-Requests: 1
Alternativ kann der Abruf der Seite auch über den Vorangegangenen Befehl erfolgen. Die Anfrage wird von Netcat jedoch nicht geprüft, so das Du bei der Anfrage auch beliebige Zeichen in die Abfrage schreiben kannst.:
metzger@linux:~$ echo -e "HTTP/1.1 200 OK\r\nContent-Type: text/html\r\n\r\nLinux, da bin ich"|nc -l 8080 & [1] 1465 metzger@linux:~$ echo -e "GET / HTTP/1.1\r\nHost: meins\r\n\r\n"|nc localhost 8080 GET / HTTP/1.1 Host: meins HTTP/1.1 200 OK Content-Type: text/html Linux, da bin ich [1]+ Fertig echo -e "HTTP/1.1 200 OK\r\nContent-Type: text/html\r\n\r\nLinux, da bin ich" | nc -l 8080
Allerdings ist der Aufruf der „Seite“ auf diese Weise nur ein einziges mal möglich!
Um einen wiederholten Abruf zu ermöglichen kannst Du das Netcat in eine Endlosschleife legen.:
while true; do echo -e "HTTP/1.1 200 OK\r\nContent-Type: text/html\r\n\r\nLinux, da bin ich"|nc -l 8080; done